This is going to be a series of blog posts where we will implement a recursive descent parser library in Scala using FastParse parser combinators for simple arithmetic expressions and cross compile the same in Javascript using Scala.js eventually utilizing it in a small Javascript application.
Before we get started, I would like to mention that the concepts and principles discussed in this blog post are borrowed from an excellent book on compiler design called, Compilers (Principles, Techniques, & Tools) by Pearson Education and that the discussions here are mostly focussed around writing/designing grammars for recursive descent parsers. I highly recommend chapters 2 and 4 from this book to complement this post. Having said that, los geht's.
Context-Free Grammars
In formal language theory, arithmetic expressions falls under the category of context-free languages which are described using context-free grammars.
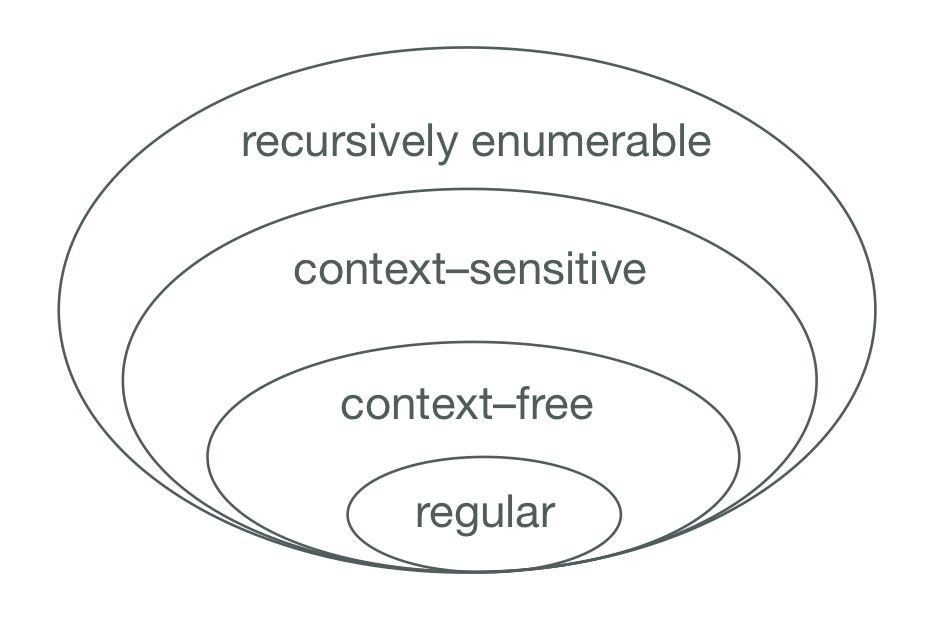
A context-free grammar can be described by a four-element tuple (T,V,R,S), where
- T is a finite set of terminals which are the elementary symbols of the language defined by the grammar
- V is a finite non-terminals which represents a set of strings of terminals
- R is a set of productions rules where each production rule maps a non-terminal to a string s∈(V∪T)∗;
- S is one of the non-terminals as the start symbol
For an example, the grammar for a language of strings that always ends in 0 could be defined as below:
T = {0,1}
V = {Z}
R = Z -> 0 | 0Z | 1Z
S = {Z}
Now so as to be able to programmatically parse any string from this language we would need a parser based out of the grammar defined above.
Recursive Descent Parsers
Parsing is basically a process of determining how a string of terminals (T) can be generated by a grammar. As part of this process, a parser should be capable of constructing a parse tree, in principles. Although, it may or may not require to construct one, in practice. Most parsing approaches fall into one of the two classes, called the top-down and bottom-up parsing. The top-down parsers construct parse trees starting at the root and proceeds towards the leaves, while the bottom-up parser starts the other way around. The top-down approach is usually a popular choice to construct efficient parsers easily for construct-free grammars. Bottom-up parsing, on the other hand, is capable of handling a wider class of grammars and is mostly a preferred choice for software tools that generate parsers directly from the grammars.
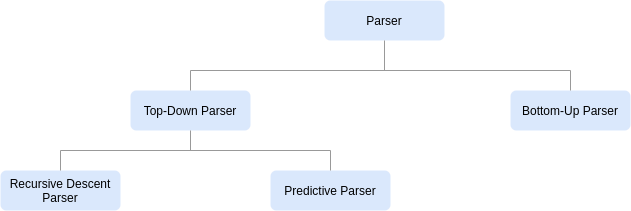
Recursive descent parsing is a top-down parsing approach in which a set of recursive procedures is used to syntactically analyse a given input. One procedure is usually associated with each non-terminal (V) of a grammar. The procedures look at its input and decide which production rule to apply for its non-terminal. Terminals in the body of the production rule are matched to the input at the appropriate time, while non-terminals in the body result in calls to respective procedures. If a sequence of procedure calls during syntax analysis is able to define a parse tree implicitly for the given input string, that string is then considered correct. Another important aspect of recursive descent parsing is that the selection of a production rule for a non-terminal usually involves trial-and-error i.e., if production rule is found unsuitable to proceed with the construction of the implicit parse tree against the given input, the procedure backtracks and retries with other available production rules.
Why not predictive parsers?
The FastParse scala library that we are going to use to write simple arithmetic parser allows us to write recursive descent parsers unlike ANTLR which uses predictive parsing technique instead, which is why we will stick with recursive parsing technique for this blog series. It's worth mentioning here that predictive parsers are essentially recursive descent parsers without backtracking and can only be implemented for LL(k) context-free grammars. However, if you already have a LL CFG, you can still parse it with non-predictive recursive descent parsers. Also, if you're to hand implement parser without the help of any tools and libraries, predictive parsing should be your first choice. Read more about it in section 4.4.3 from Compilers (Principles, Techniques, & Tools) book.
Writing Grammar
Writing grammar for a language is a bit more involved process. Just like designing a relational database requires attention to certain aspects such as eliminating data redundancy, ensuring data integrity and accuracy, etc; there are certain similar aspects to writing/designing grammar for a type of language. Let's walk through those aspects while building our grammar simultaneously.
Associativity of Operators
When an operand has operators both to its left and right, it is the operator associativity that dictates which operator applies to that operand. We say that the operator + associates to the left, because an operand with + operator on either side belongs to the operator to its left. Similarly, the operator = associates to the right, because an operand with = operator on either side belongs to the operator to its right. The associativity of operators, as one of the dictating factors, decides how production rules for a grammar are written and how a given string is consequently parsed as tree.
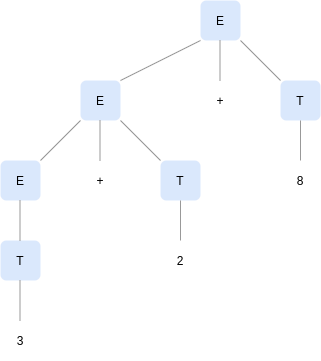
For instance, strings like 3+2+8 are generated by the following grammar:
E -> E + T | T
T -> Num
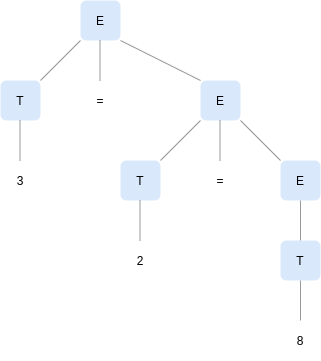
While strings like 3=2=8 are generated by the following grammar:
E -> T = E | T
T -> Num
Precedence of Operators
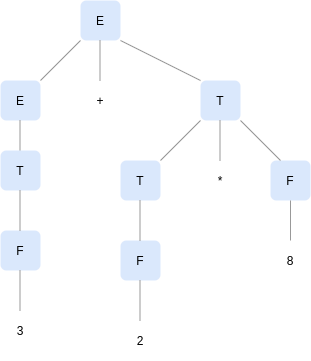
When an operand has different operators to its left and right, it is the precedence of operators that dictates which of the two operators apply to that operand. For example, the operand 2 in string, 3 + 2 * 8, belongs to * operator, such that, the string is evaluated as 3 + (2 * 8) and not (3 + 2) * 8. The grammar has to express the same by creating as many non-terminals as there are levels of operator precedence and production rules to capture the same. In our language of simple arithmetic expressions, we have two such levels of precedence:
+ - (left associative)
* / (left associative)
and the pertaining productions rules to capture these levels of precedence would be:
E -> E + T | E - T | T
T -> T * F | T / F | F
F -> Num | (E)
Eliminating Ambiguity
When a grammar can have more than one parse tree generating a given string of terminals, it is said to be ambiguous. Consider the grammar below to construct if-then-else statements:
S -> if E then S | if E then S else S | S'
Here, E stands for a boolean expression and S' for statements other than if-then-else. This grammar is ambiguous since the string if E1 then if E2 then S1 else S2 can be derived from following two parse trees:
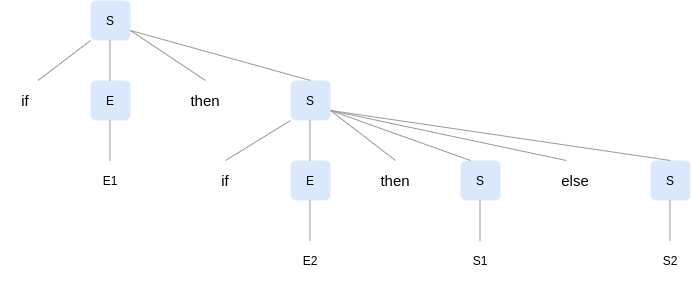
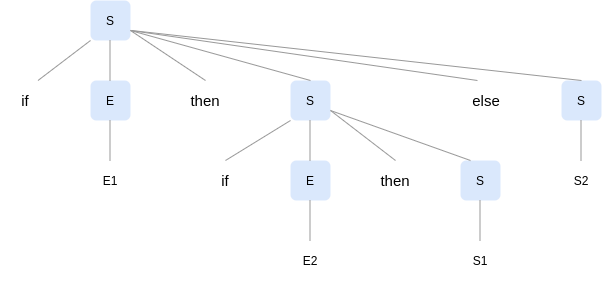
Generally, adding more production rules that clearly indicate legal case resolves ambiguity. In this particular case, the first amongst the two parse trees is considered a legal construct in most programming languages. This translates into a general rule wherein any conditional statement appearing between a then and an else must always have a then which has a pairing else, also referred to as matched statements. Rewriting our grammar as follows takes care of this rule and avoids any ambiguity:
S -> M | O
M -> if E then M else M | S'
O -> if E then S | if E then M else O
Here, M stands for matched statements while O stands for statements for open statements.
The grammar we defined in the last section for our language of simple arithmetic expressions doesn't have any such ambiguities. Therefore, we will keep it as is for this section.
Eliminating Left Recursion
A grammar is called left recursive if it has production rules wherein the leftmost symbol of the body is the same as the non-terminal at the head of the production. An example of such a rule would be E -> E + T. The problem with left recursive grammars is that they lead top-down parsers into non-terminating recursive calls Refer section 2.4.5 from Compilers (Principles, Techniques, & Tools) book for more details.
However, all hopes aren't lost. Such offending production rules can be rewritten to eliminate left-recursion. Consider a non-terminal A with two productions
A -> Aα | β
where α and β are sequences of terminals and non-terminals that do not start with A. We can rewrite the same as follows to eliminate left-recursion:
A -> βR
R -> αR | ε
It is also worth mentioning here that the resulting R productions are right-recursive in nature but never leads top-down parsers into non-terminating recursive calls. Another important thing here to make note of is that left-recursions in productions may not be immediate. For example, consider the grammar
S -> Aa | b
A -> Ac | Sd | ε
The non-terminal S is left-recursive because of derivation like S => Aa => Sda. Such grammars can be rewritten to eliminate non-immediate left-recursion as follows. Refer algorithm 4.19 from Compilers (Principles, Techniques, & Tools) book for details:
S -> Aa | b
A -> bdA' | A'
A' -> cA' | adA' | ε
The grammar for our language of simple arithmetic expressions after elimination of left-recursive productions would look like:
E -> TE'
E' -> +TE' | -TE' | ε
T -> FT'
T' -> *FT' | /FT' | ε
F -> Num | (E)
Left Factoring
When the choice between alternative productions is not clear, we can rewrite them to defer the decision of choosing an appropriate production until enough of the input has been seen. This grammar transformation is called as Left factoring. For example, consider following productions:
S -> if E then S else S | if E then S
Evidently looking at the terminal if, the choice is not very clear.
In general, for a given non-terminal A with two productions:
A -> αβ1 | αβ2
left factoring would involve rewriting the productions as follows
A -> αA'
A' -> β1 | β2
The grammar for our language of simple arithmetic expressions doesn't require left factoring.
Conclusion
So far we have touch upon all the aspects necessary to write a suitable grammar for recursive descent parsers. We will take the grammar that we have built and continue building a recursive descent parser library in the next post.